



Overgangen fra generativ KI til agentisk KI går raskt. I SINTEF AgentLab eksperimenterer vi med agentisk koding i egne prosjekter for programvare og vitenskapelig modellering. I dette innlegget deler vi hvor vi ser de største mulighetene fremover.
Som mange lesere sikkert har fått med seg, er KI i ferd med å endre hvordan arbeid utføres innen programvareutvikling og vitenskapelige beregninger. Systemene er ikke lenger begrenset til å svare på instruksjoner eller generere enkeltstående kodebiter. I økende grad kan de planlegge oppgaver, bruke verktøy, teste resultater og forbedre løsningen underveis, med varierende grad av autonomi.
I SINTEF AgentLab eksperimenterer vi med agentisk koding i våre egne programvareprosjekter, bygger agentiske grensesnitt mot vitenskapelige modelleringsverktøy og undersøker hvordan tilsvarende tilnærminger kan brukes på nye anvendelsesområder.
Overgangen fra generativ KI til agentisk KI er en reell kvalitativ endring, og utviklingen går raskt.
Fra generering til orkestrering: hva skiller agentisk KI fra annen KI?
For mange er KI i dag først og fremst språkmodellbaserte verktøy som man gir en instruksjon for å få et resultat: en tekst, litt kode, et bilde eller et svar. ChatGPT og Microsoft Copilot er opplagte eksempler. Slike verktøy kan være svært nyttige, men samspillet er fortsatt i stor grad basert på én og én utveksling. Modellen produserer et svar, og mennesket må vurdere det, justere instruksjonen, teste resultatet og bestemme hva som skal gjøres videre.
Med agentisk KI mener vi KI-systemer som ikke bare genererer et enkelt svar, men som kan arbeide mot et mål over flere trinn.
En agent kan dele en oppgave inn i deloppgaver, bruke verktøy, undersøke delresultater og tilpasse neste handling deretter. Dermed endres samspillet: I stedet for å produsere ett svar og stoppe, fortsetter agenten til oppgaven er løst, eller til den møter et problem den ikke klarer å håndtere.
Grunntanken er ikke ny. Det som har endret seg, er at dagens modeller er langt bedre til å håndtere lengre handlingsforløp på en måte som faktisk er nyttig i praksis. De er bedre til å strukturere oppgaver, holde oversikt over fremdrift, bruke tilbakemeldinger og gjenkjenne i hvert fall noen typer feil.
Dette endrer også menneskets rolle. I stedet for å utføre hvert enkelt trinn direkte, definerer mennesket målet, setter rammer og vurderer resultatet. Arbeidet fjernes ikke fra menneskelig kontroll, men kontrollen flyttes oppover: bort fra trinnvis utførelse og over mot mål, rammer og kvalitetssikring.
Utviklingstakten er høyere enn de fleste organisasjoner er klar over. Agentiske systemer har blitt betydelig bedre det siste året, og mye av denne fremgangen er lett å gå glipp av hvis man ikke tester verktøyene selv. Figur 1, basert på referansemålinger fra METR, gir én måte å se utviklingen på. Den viser hvor komplekse programvareoppgaver KI-modeller kan løse pålitelig, uttrykt som hvor lang tid den samme oppgaven ville tatt for en menneskelig ekspert.
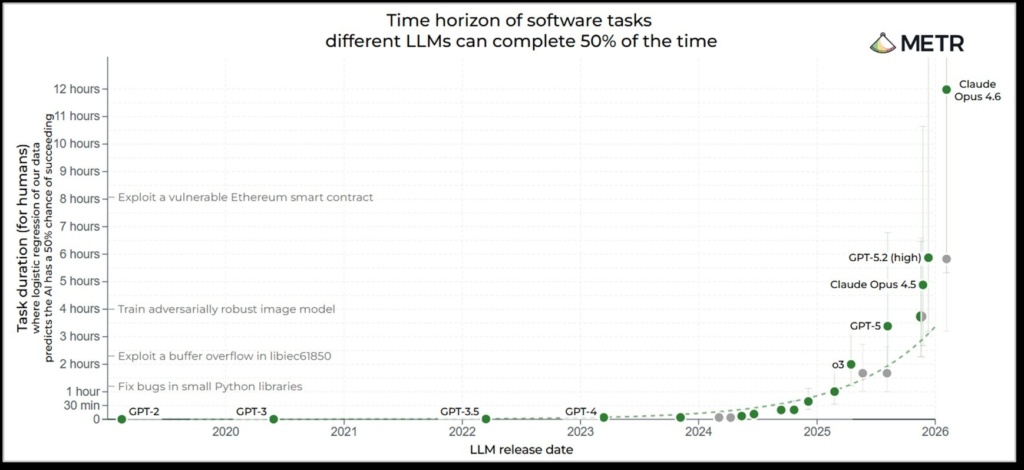
Figur 1. Oppgavehorisonten for KI-modeller øker. Y-aksen viser tiden en menneskelig ekspert ville brukt på den samme oppgaven; x-aksen viser når språkmodellene ble lansert. Den bratte økningen fra 2024 og fremover er tydelig. Kilde: metr.org/time-horizons
Siden 2024 har denne oppgavehorisonten økt kraftig. I noen tilfeller kan oppgaver som ville tatt en fagekspert en hel arbeidsdag, nå løses korrekt av en KI-agent på under en time. Samtidig er det viktig å ikke overtolke referansemålingen. Oppgavene i figuren stopper ved om lag 12 timer, og standardiserte evalueringer fanger ikke opp hele bredden av arbeid som er relevant i vitenskapelig programvare.
I våre egne prosjekter ville flere av eksemplene vi diskuterer nedenfor trolig tatt en erfaren utvikler langt lengre tid å bygge fra bunnen av. Det tyder på at det praktiske taket for veldefinerte vitenskapelige oppgaver allerede kan ligge høyere enn dagens referansemålinger klarer å vise.
Dette har betydning fordi det endrer hvor verdien ligger i programvare. Når kode blir enklere og billigere å produsere, blir grunnleggende funksjonalitet mindre særegent og er ikke lenger et tydelig konkurransefortrinn. Det som betyr mer, er fagkunnskap, kuraterte data, etablerte arbeidsflyter og dømmekraften som trengs for å formulere riktig problem og vurdere resultatet.
Vibe-koding og agentisk koding er ikke det samme
Det er lett å omtale all KI-støttet koding som om det var omtrent det samme. I praksis er det ikke slik.
Det er en viktig forskjell mellom det som ofte kalles «vibe-koding», og det vi her beskriver som agentisk koding.
Vibe-koding er i stor grad prompt-drevet og improvisert. Utvikleren ber om noe, aksepterer det modellen produserer, tester det kanskje uformelt og går videre. Det kan være nyttig til raske prototyper, eksperimenter eller engangsskript. Men alene er det ikke en pålitelig vei til produksjonsklar programvare.
Agentisk koding fungerer annerledes. Agenten arbeider mot et definert mål ved å planlegge, utføre, teste og revidere fremgangsmåten. Den jobber i løkker, ikke med én prompt om gangen, og kontrollerer resultatet mot eksplisitte eller utledede kriterier før den erklærer oppgaven som løst. Mennesket definerer oppgaven og vurderer resultatet, men trenger ikke styre hvert enkelt trinn i prosessen.
Dette handler heller ikke bare om bedre autofullføring.
Det vesentlige er fremveksten av en mer strukturert utviklingsprosess, som i mange tilfeller kan gi overraskende robuste resultater, også for komplekse og ganske åpne oppgaver.
Noe av det som har slått oss flere ganger, er agentens evne til selv å komme opp med nyttige tester og suksesskriterier, og til å forbedre dem etter hvert som den får bedre forståelse av problemet.
Det er også verdt å merke seg at agentisk KI ikke må bety én agent som arbeider alene. Mer komplekse oppgaver kan fordeles på flere spesialiserte agenter med ulike roller. Én kan hente kontekst og tidligere arbeid, en annen dele oppgaven inn i trinn, en tredje implementere og kjøre kode, og en fjerde verifisere resultatet og dokumentere hva som ble gjort. Også i et slikt oppsett beholder mennesket kontrollen, men på et høyere nivå.
Hva SINTEF har lært av agentisk koding i praksis
Vi har testet disse verktøyene på et bredt spekter av reelle utviklingsoppgaver. Eksemplene nedenfor spenner fra kode i simulatorer som brukes operasjonelt av Equinor, til avanserte numeriske algoritmer, beregningsgeometri, domenespesifikke simulatorer og rask prototyping. Vi tar også med et eksempel på hvordan agenter kan brukes som grensesnitt mot avanserte modelleringsverktøy. Til sammen gir eksemplene et tydeligere bilde av hva agentisk KI allerede kan gjøre innen vitenskapelig programvare og modellering.
Agentisk koding i en simulator som brukes operasjonelt
OPM Flow er en C++-basert reservoarsimulator med åpen kildekode som brukes operasjonelt på norsk sokkel. Den er utviklet gjennom mer enn 15 år i et stort samarbeid mellom blant andre Equinor, NORCE, SINTEF og TNO. Kodebasen inneholder om lag en halv million kodelinjer. Dette er med andre ord ikke en demo eller en forskningsprototype, men et stort og etablert programvaresystem. Dermed er OPM Flow også et svært relevant utgangspunkt for å vurdere hvordan agentisk koding fungerer i reell programvareutvikling.
Vi utviklet planen sammen med agenten, gikk nøye gjennom den og lot den deretter utføre implementeringen. Hele oppgaven ble fullført og validert i løpet av 30 minutter, uten feil. Figur 2 viser agentens arbeidsflate under planlegging og implementering: til venstre integrasjonsplanen og målarkitekturen; til høyre senere implementeringstrinn, det GPU-forberedte designet og den ferdige oppgavelisten.
Dette eksempelet gjør ikke eksperten mindre viktig. For en så inngripende oppgave i et etablert programvaresystem er tett gjennomgang og domenefaglig vurdering fortsatt avgjørende. Det som endrer seg, er arbeidets karakter: Eksperten bruker mindre tid på manuell implementering og mer tid på arkitektur, designmønstre og vurdering av alternativer. Det gjør det mulig å utforske flere muligheter, noe som kan gi bedre designvalg og høyere kodekvalitet uten at man mister den dype forståelsen som følger av å være tett involvert.
Også gjennomgangen endrer karakter. Eksperten trenger ikke nødvendigvis å inspisere hver eneste endring linje for linje for å tilføre verdi. Mer av innsatsen kan i stedet rettes mot å kontrollere at implementeringen følger den tiltenkte arkitekturen og oppfyller relevante begrensninger og valideringskriterier.
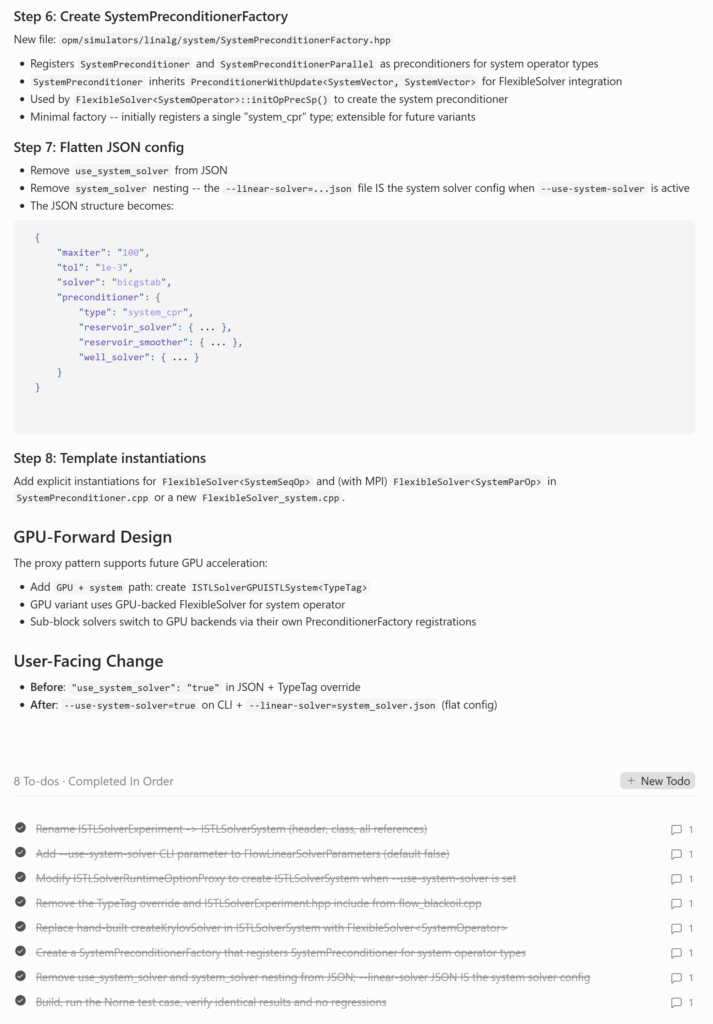
Figur 2. Agentens arbeidsflate under planlegging og implementering av endringen i OPM Flow. Til venstre vises den foreslåtte integrasjonsplanen og målarkitekturen; til høyre senere implementeringstrinn, designnotater og den ferdige oppgavelisten. Figuren viser at agenten ikke bare genererer kode, men arbeider seg gjennom en strukturert prosess med planlegging, utførelse og verifisering.
En ruteplanlegger med intuitivt grensesnitt, bygget på en helg
Vi testet også hvor langt agentisk koding kunne ta oss i å bygge en liten ruteplanleggingsapplikasjon fra bunnen av. Resultatet ble et enkelt, men funksjonelt VRP-verktøy, altså et verktøy for kjøretøyruting, med interaktiv kartvisning, ordrehåndtering, mulighet til å beregne ruter på nytt og avspilling av simuleringer – alt bygget på kort tid med noen få direkte instruksjoner.
Dette var ikke Spider, SINTEFs egen løser for kjøretøyruting, og det var heller ikke ment å være det. Spider er utviklet over tre tiår og inngår i kommersielle logistikksystemer som brukes daglig over hele Norden. Det vi bygde, var langt enklere: en lett ruteplanlegger med et intuitivt grafisk grensesnitt som viser noe av potensialet i teknologien.
Når det er sagt, hadde vår lange erfaring med Spider stor betydning. Den gjorde at vi visste hva vi skulle be om, hvordan en fornuftig arbeidsflyt burde se ut, og hvordan vi kunne vurdere om det genererte systemet faktisk var nyttig. Denne fagkunnskapen var en viktig del av forklaringen på at resultatet fungerte så godt som det gjorde.
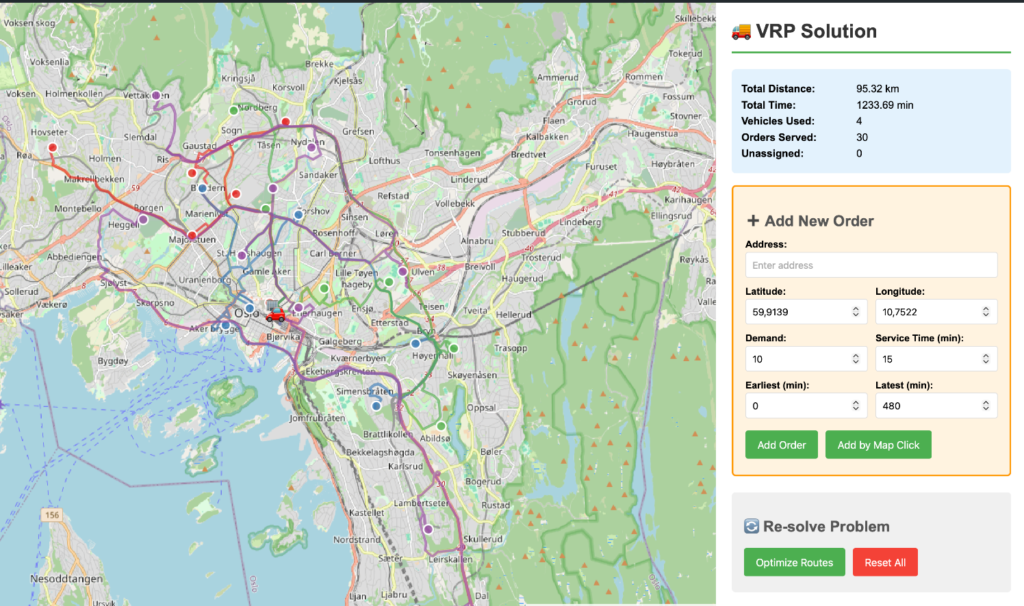
Figur 3. En enkel ruteplanleggingsdemo bygget på én dag. Grensesnittet viser beregnede kjøretøyruter i Oslo-området, der 30 ordre betjenes av fire kjøretøy. Nye ordre kan legges til interaktivt, og løsningen kan optimaliseres på nytt ved behov.
Beregningsgeometri: tett samarbeid og gradvis forbedring
løpet av en uke, ved siden av ordinært arbeid, utviklet en av oss et sett avanserte beregningsgeometriske verktøy for prosessering av grid i Jutul familien av simulatorer for strømning i undergrunnen. Arbeidet omfattet generering av 3D cut-cell-grid fra rektangulære grid og hjørnepunktsgrid, to gridformater som brukes mye i undergrunnsmiljøet. Det omfattet også sammenkobling av ikke-konforme grid med plane flater, implementering av lokal gridforfining og nesting av et grid inni et annet. Figur 4 viser to eksempler på de resulterende gridene.
Dette var en viktig suksess for oss, men det illustrerer også noe som er like viktig ved agentisk koding: I vanskelig algoritmisk arbeid er det sjelden nok å overlate oppgaven til agenten og gå sin vei. Mennesket må være involvert, kontrollere resultatene nøye og forvente flere runder med justering og forbedring før resultatet kan stoles på.
I slikt arbeid kan koden kjøre uten feilmeldinger og likevel gi feil svar. Å oppdage det krever domeneekspertise, visuell inspeksjon og aktiv deltakelse i utviklingsprosessen. Claude Opus 4.6 var imponerende i hvor godt den kunne planlegge og utføre en stor, strukturert oppgave, men bare under nøye menneskelig oppfølging.
Til slutt beholdt vi de delene av den genererte koden som virket verdifulle nok til å vedlikeholde, og forkastet resten. Det er trolig den riktige måten å forstå denne typen samarbeid på: ikke som full automatisering, men som en måte å komme raskere frem i krevende teknisk arbeid samtidig som ekspertvurderingen holdes inne i løkken.
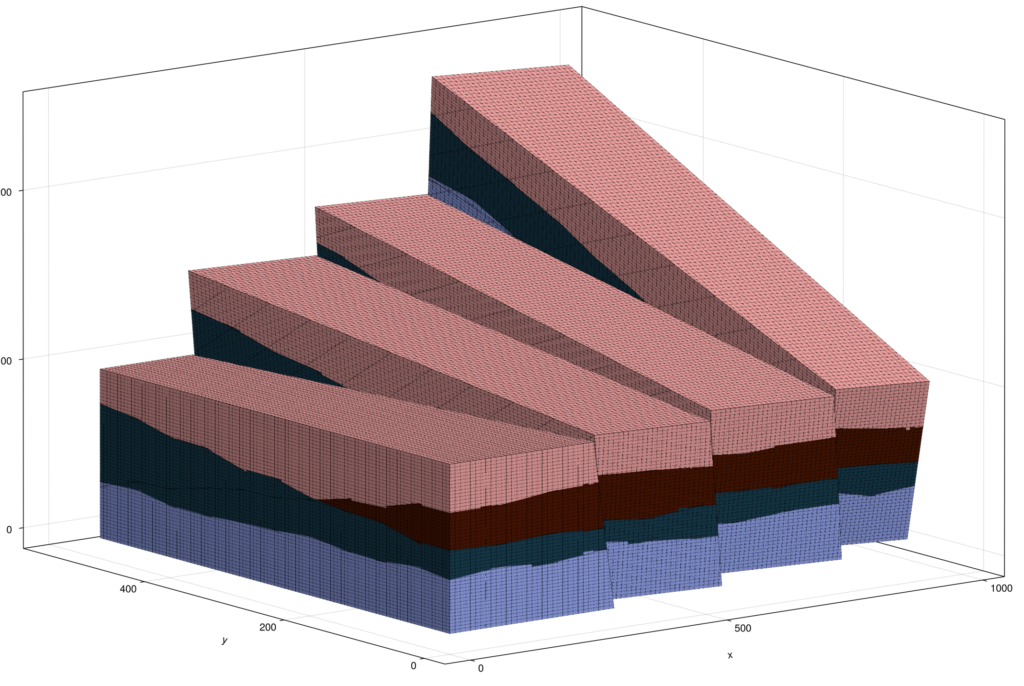
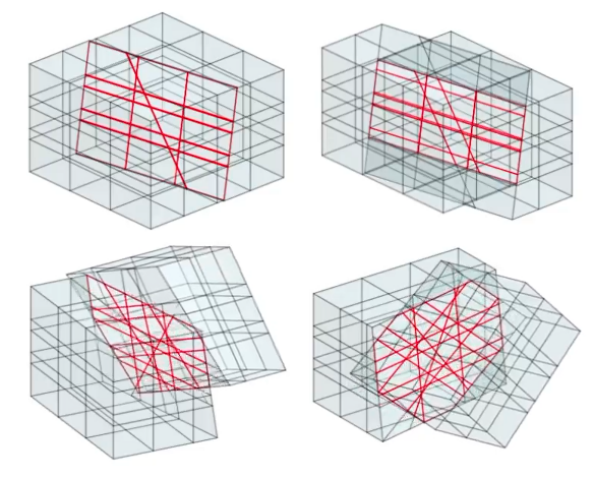
Figur 4. To eksempler fra arbeidet med beregningsgeometri. Til venstre: et hjørnepunktsgrid med forkastningsblokker og flere stratigrafiske lag, generert fra gridformater som brukes i undergrunnsmodellering. Til høyre: sammenkobling av ikke-konforme grid, der et rektangulært grid er kuttet i to og de to halvdelene er forskjøvet og rotert i forhold til hverandre langs et snittplan. De røde linjene viser den polyedriske skjæringsgeometrien som må beregnes riktig for at koblingen skal være gyldig.
Grafisk grensesnitt for en overvannssimulator – og en lærdom om arbeidsmåte
SWIM er SINTEFs Julia-pakke med åpen kildekode for statisk modellering og prediksjon av overvannsflom, basert på nedbørfelt- og spillpunktanalyse av terrengtopografi. I motsetning til full hydrodynamisk simulering gir denne tilnærmingen svar nesten umiddelbart, noe som gjør den godt egnet til interaktiv utforskning av flomscenarier. I praksis er dette viktig for byplanleggere og forskere innen klimatilpasning, som ofte trenger å teste mange scenarier raskt.
I dette tilfellet var den konkrete konteksten SUrbArea prosjektet, som har som mål å redusere samfunnsrisiko i et klima i endring gjennom naturbaserte løsninger i bærekraftig byutvikling. Prosjektet trengte et grensesnitt som gjorde det mulig for partnerkommunene å arbeide direkte med SWIM-programvaren. Det grafiske brukergrensesnittet som ble bygget med agenten, vist i figur 5, legger til et fullverdig interaktivt 3D-grensesnitt med terrengvisualisering, konfigurerbare overflatelag, objektlag for bygninger og veier, visning av dreneringsmønster og simuleringskontroller.
Dette eksempelet lærte oss også noe om hvordan man bør arbeide med en agent. Grensesnittet ble utviklet under svært tett menneskelig kontroll, der agenten aldri fikk mer arbeid enn det som komfortabelt kunne gjennomgås av utvikleren i ett trinn. Det ga høyt forbruk av tokens og var, basert på det vi så i andre prosjekter, trolig både dyrere og mindre effektivt enn nødvendig.
På tvers av flere prosjekter har vi generelt sett bedre resultater når oppgaven defineres tydelig på et høyere nivå og agenten får mer rom til å planlegge og utføre. Det er da evnen til å resonnere om struktur, foreslå fornuftige mellomtrinn og formulere nyttige valideringskriterier ser ut til å ha størst betydning.
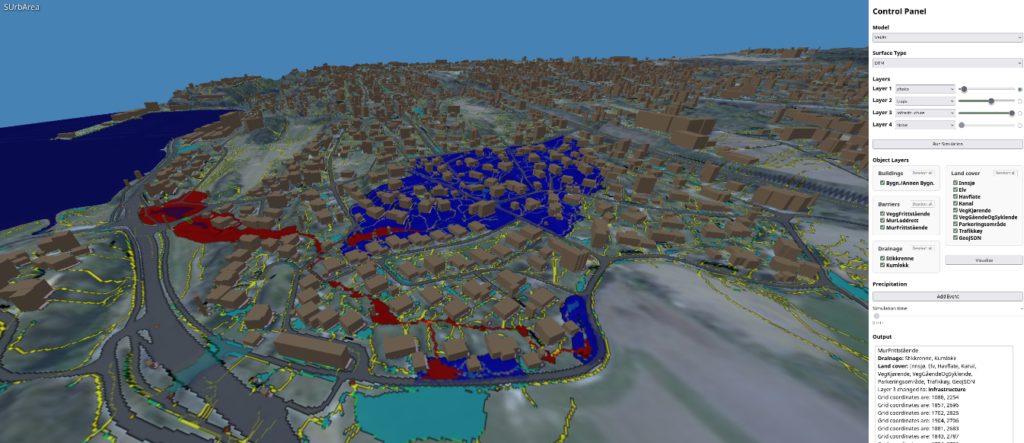
Figur 5. Et interaktivt 3D-grensesnitt for SINTEFs SWIM-verktøy, her vist for området rundt Hvalstad stasjon i Asker kommune. Grensesnittet visualiserer hvordan terreng og infrastruktur påvirker drenering og vannansamling under kraftig nedbør, og har kontroller for terrenglag, objektlag og simuleringsinnstillinger. Dataene i eksempelet ble opprinnelig hentet fra Kartverket.
Hvor raskt nye verktøy nå kan bygges
De neste to eksemplene ble bygget til en demo vi ble bedt om å forberede, med knapt mer enn én dag til rådighet. De ble utviklet parallelt på én enkelt arbeidsstasjon. Den korte tidsrammen var bevisst: En del av det vi ønsket å teste, var hvor raskt nyttige nye verktøy kunne settes sammen.
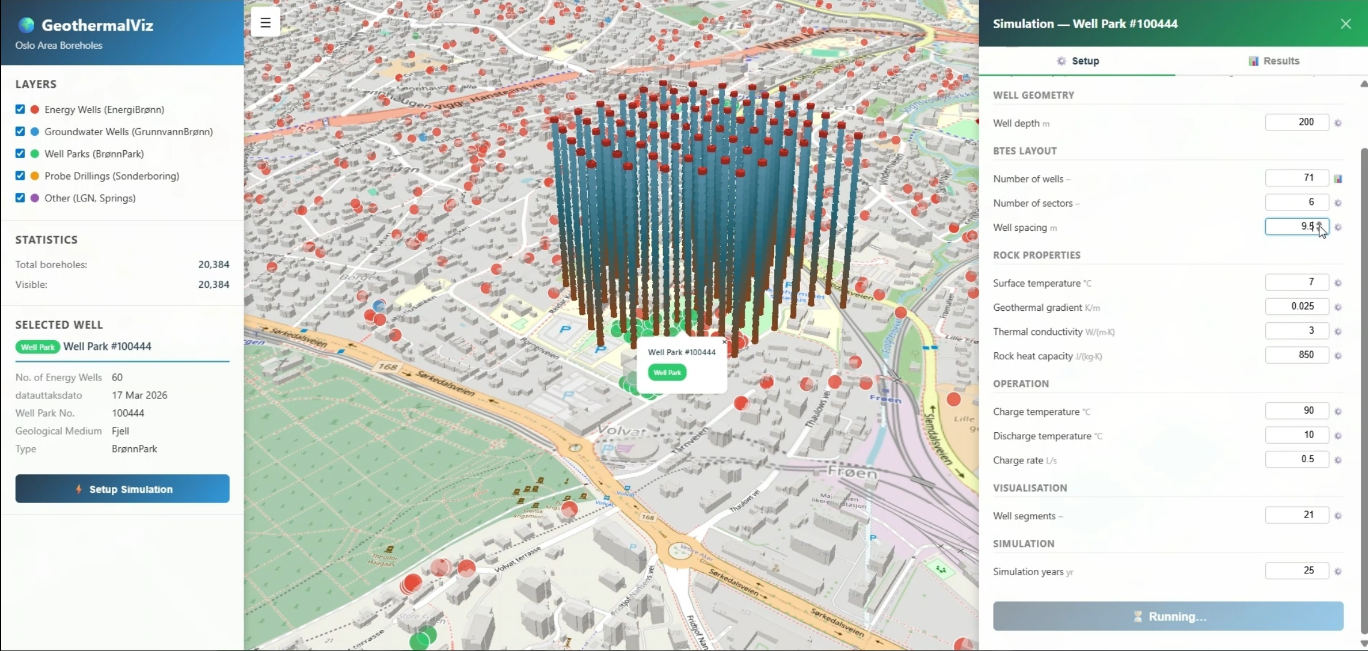
Det første verktøyet ble bygget for å vise hvor raskt man kan lage et nyttig interaktivt grensesnitt rundt et eksisterende vitenskapelig programvareprodukt. I dette tilfellet var produktet Fimbul.jl, SINTEFs Julia-pakke med åpen kildekode for simulering og analyse av geotermiske reservoarer og systemer for termisk energilagring. Verktøyet bruker åpne brønndata fra Norges geologiske undersøkelse (NGU) og visualiserer alle tilgjengelige brønner i et valgt område i et interaktivt 3D-kart. Det lar brukerne utforske og omkonfigurere geotermiske brønnanlegg, samtidig som de får bedre forståelse av dataene som brukes som inngang til simulatoren. Figur 6 viser et eksempel der et anlegg med 60 brønner ble omkonfigurert og brukt til å sette opp en simulering.
Poenget var å vise hvordan modelleringsverktøy som Fimbul kan gjøres mer tilgjengelige gjennom et grafisk grensesnitt og direkte kobling til åpne offentlige data. Den nåværende koblingen til Fimbul fungerer for enkle oppsett, mens en mer fullstendig integrasjon fortsatt er under utvikling. Eksempelet viser også én måte agentisk KI kan brukes ansvarlig i vitenskapelig programvare på: Agenten bygger grensesnittlaget og kobler sammen datakilder, visualiseringer og brukerinteraksjon, mens selve beregningene fortsatt utføres av simulatorer vi har utviklet og validert gjennom mange år. Det gjør det enklere for fageksperter som geologer og energiplanleggere å arbeide direkte med simulatoren, uten å måtte lære det interne API-et.
Det andre eksempelet var svært annerledes. Den 16. mars 2025 brøt det ut en skog- og lyngbrann på Sukkertoppen i Ålesund, noe som førte til evakuering av 450 innbyggere. Samme dag begynte vi å bygge et enkelt verktøy for brannsimulering. Dette lå utenfor våre vanlige anvendelsesområder, og var derfor en nyttig test av hvor langt en agent kunne komme fra en overordnet problembeskrivelse.
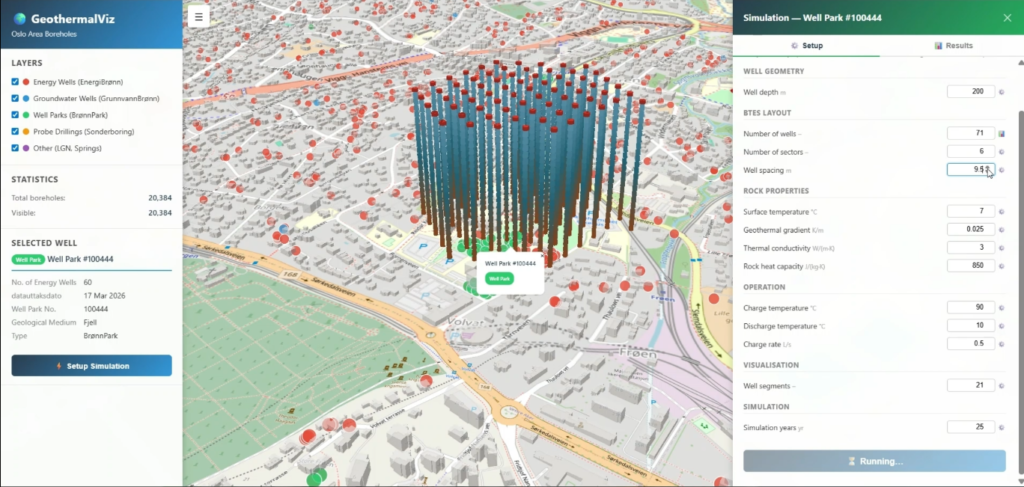
Figur 6. Et interaktivt verktøy for geotermisk simulering som kombinerer åpne brønndata fra NGU med Fimbul-simulatoren. Brukerne kan utforske eksisterende brønner, utforme nye konfigurasjoner og sette opp simuleringer gjennom et grafisk grensesnitt.
Oppgaven ble bevisst holdt åpen. I stedet for å spesifisere en detaljert løsning ga vi agenten en overordnet beskrivelse av problemet og ba den finne en gjennomførbar tilnærming. Den hentet inn vitenskapelig litteratur om modeller for brannspredning basert på cellulære automater, identifiserte egnede modeller, skaffet åpne data om kystlinjer, arealdekke og terreng, og implementerte simuleringen i Julia. Figur 7 viser resultatet.
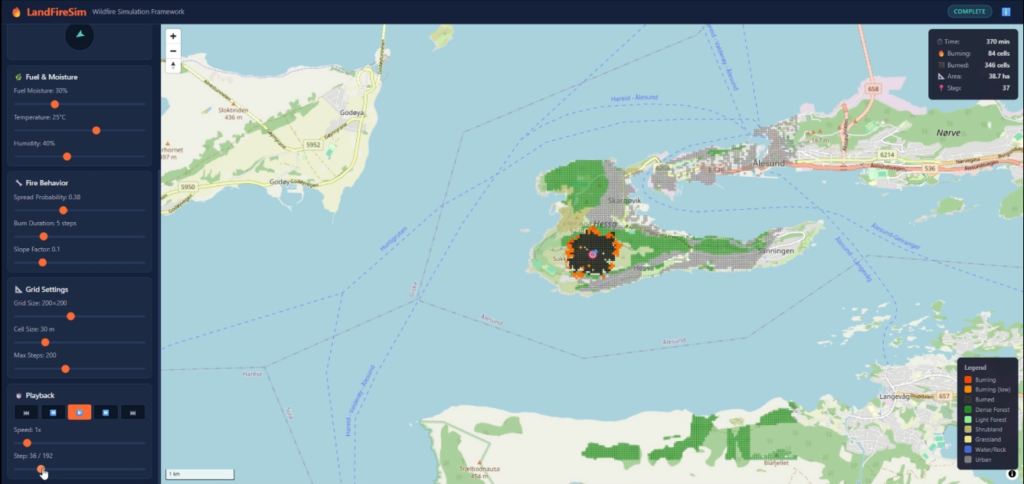
Figur 7. Et brannsimuleringsverktøy bygget i Julia på omtrent én dag ved hjelp av åpne datasett. Verktøyet kan sette opp simuleringer for områder over hele verden, og er vist her for Sukkertoppen i Ålesund, der det brøt ut en reell skog- og lyngbrann 16. mars 2025. Oransje celler brenner aktivt, svarte celler er utbrente, og grønne celler viser skogdekke.
Et forbehold er på sin plass. Dette er bare en demo, ikke et validert verktøy. Før det kan brukes operasjonelt, må selvsagt den underliggende modellen gjennomgås grundig og valideres mot dokumenterte brannhendelser, datakildene måtte kontrolleres for nøyaktighet på relevant skala, og modellresultatene måtte kalibreres mot observert brannatferd. Poenget med dette eksperimentet er ikke at agenten produserte en bruksferdig simulator på én dag, men at den ga oss et troverdig utgangspunkt – i stor grad på egen hånd og basert på en overordnet problembeskrivelse..
Vi fullførte også flere andre moduler og verktøy. Blant disse var en JutulDarcy-løser for beregning av tidslinjer og avgrensning av strømningsregioner i reservoarer (flytdiagnostikk) reimplementasjon av den virtuelle elementmetoden fra vår åpne MRST simulator i Jutul, resultatplotter for OPM Flow og visualisering av strømningsløsninger for flersegmentbrønner. Disse nevnes bare kort her, slik at de mer krevende eksemplene kan få større plass.
Draugr: en AMG-løser i Julia bygget over natten
Storskala simulering av fysiske prosesser – enten det gjelder strømning i undergrunnen, strukturmekanikk, klimamodellering eller batteriteknologi – handler ofte om å løse store systemer av lineære ligninger. Dette er vanligvis en av de mest beregningskrevende delene av arbeidsflyten, og løserytelsen kan avgjøre om en simulering i det hele tatt er praktisk gjennomførbar, og i hvilken skala. Algebraisk multigrid (AMG) er en av de ledende metodene for denne typen problemer, fordi metoden kan oppnå nær optimal kompleksitet på tvers av et bredt spekter av anvendelser. For et seriøst simuleringsrammeverk er en effektiv AMG-implementering derfor en kjernefunksjon.
En mye brukt referanseimplementering er hypre, utviklet ved Lawrence Livermore National Laboratory gjennom flere tiår med vedvarende finansiering og dyp spesialistkompetanse. Vi ba en agent utvikle en tilsvarende AMG-modul for Jutul-rammeverket vårt, som utgjør det felles beregningsgrunnlaget for arbeidet vårt innen reservoarsimulering, geotermisk energi, batterier og andre domener. Den nye løseren fikk navnet Draugr.
Spesifikasjonen var tydelig på hvilke arkitekturvalg som var nødvendige for GPU-kompatibilitet, og prosessen var reelt samarbeidende. Vi bidro med egne tester og verifikasjonsresultater mot en referanseimplementering, som agenten brukte til å styre de videre rundene med forbedring. Det er viktig å være tydelig på omfanget her: Modulen retter seg mot skalarproblemer av den typen som oppstår i våre simulatorer, og inkluderer ikke MPI-parallellisme, som står for en stor del av kompleksiteten i hypre. Selv med dette smalere omfanget var det oppsiktsvekkende å få en plattformuavhengig implementering til å fungere over natten – på CPU, GPU og Apple Metal, og på tvers av Windows, macOS og Linux.
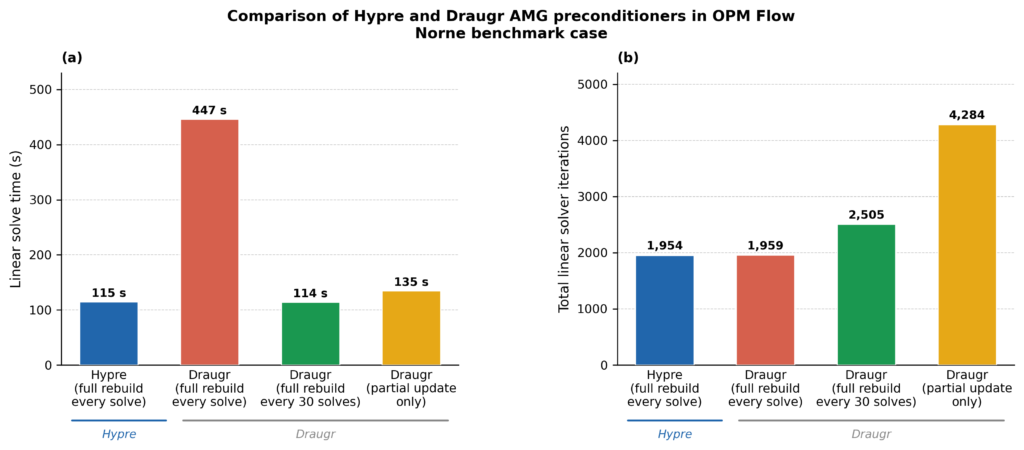
Figur 8. Sammenligning av AMG-prekondisjonerere fra hypre og Draugr kjørt i OPM Flow på Norne-feltet. (a) Veggklokketid for lineærløseren og (b) totalt antall lineærløseriterasjoner. Draugr med full bygging av hierarki hver 30. løsning matcher hypre på begge mål.
Draugr er oppmuntrende konkurransedyktig med hypre på et representativt sett av testtilfeller. Referanseimplementeringen har imidlertid fortsatt en fordel i tiden det tar å sette opp løseren og er marginalt raskere i enkelte anvendelser av prekondisjonereren, mens Draugr er designet for raskt re-oppsett, noe som er viktig i våre simuleringsarbeidsflyter. Figur 8 viser en sammenligning. Sammenligningen er ikke helt epler mot epler, og videre testing pågår fortsatt, men resultatet er likevel bemerkelsesverdig:
En målrettet, domenespesifikk AMG-modul, konkurransedyktig på sin tiltenkte problemklasse, ble utviklet i løpet av én natt.
Implementeringen er i stor grad en portering av ideer fra hypre, som er utgitt under en liberal åpen kildekode-lisens. Det peker på et bredere spørsmål. Når agenter kan reprodusere algoritmer og implementeringsmønstre svært raskt, blir spørsmål om opphav, proveniens og lisensiering viktigere, ikke mindre – særlig i tilfeller der det opprinnelige kildematerialet ikke nødvendigvis har like åpne lisensvilkår.
Agenter som grensesnitt mot vitenskapelige simulatorer
Vi utforsker også agentisk KI, ikke bare for programvareutvikling, men som grensesnitt mot vitenskapelige simulatorer. Dette er motivasjonen bak JutulGPT, en LLM-agent koblet direkte til reservoarsimulatoren vår, JutulDarcy. Agenten tar imot beskrivelser av simuleringsscenarier på naturlig språk, tolker brukerens intensjon, genererer nødvendig kode og validerer resultatet ved å forsøke å kjøre simuleringen. Når den møter uklarheter, ber den om avklaring. Når den oppdager feil, prøver den på nytt og retter dem.
Dette er en annen type oppgave enn vanlig agentisk koding. I programvareutvikling kan korrekthet ofte kontrolleres mot tester. I oppsett av simuleringsmodeller er tilbakemeldingen svakere: En modell kan kjøre ferdig og likevel være vitenskapelig feil. JutulDarcy hjelper her ved å håndheve interne konsistenskontroller for massebevaring, lukningsrelasjoner og løserkonvergens, slik at en fullført kjøring i det minste er fysisk konsistent. Det garanterer likevel ikke at modellen samsvarer med brukerens fulle vitenskapelige intensjon. Derfor er håndtering av uklarheter og menneskelig oppfølging fortsatt viktig.
Figur 9 viser et enkelt eksempel: en heterogen 3D-reservoarmodell generert fra ett avsnitt med beskrivelse på naturlig språk. I dette tilfellet ble agenten bedt om å arbeide i interaktiv modus, der den skulle sjekke med brukeren hver gang den støtte på beslutninger som ville ha vesentlig betydning for modellen. En grundigere omtale av JutulGPT, inkludert begrunnelsen for designet, hva vi lærte, og en diskusjon av reproduserbarhet og tillit, finnes i et tilhørende blogginnlegg og vår nylige arXiv-artikkel.
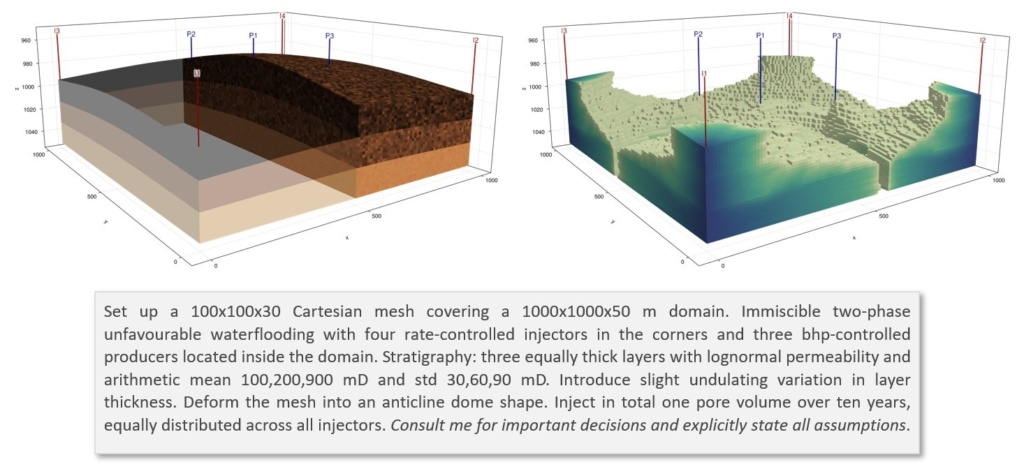
Figur 9. Et scenario med vannflømming laget av JutulGPT fra en spesifikasjon gitt i naturlig språk, som vist under resultatene. Panelet til venstre viser modellgeometrien og heterogeniteten; panelet til høyre viser hvordan vannet har spredd seg gjennom reservoaret etter at det injiserte vannet har nådd produsentene.
Hva betyr dette i praksis?
Eksemplene i dette innlegget peker i to retninger samtidig. De viser hva agentisk KI allerede kan gjøre innen programvare og vitenskapelige beregninger, men sier også noe bredere om hvor denne teknologien kan få betydning fremover, hvilke forutsetninger ansvarlig bruk krever, og hva dette kan bety for forskere, samarbeidspartnere i industri og offentlig sektor og andre kunnskapsintensive organisasjoner.
Utover programvare: agentisk KI i kunnskapsarbeid
Programvare er bare det første området der agentisk KI blir vanskelig å overse.
Det dypere mønsteret er at disse systemene kan lære og utføre arbeid som følger en gjenkjennelig metode og kan kontrolleres underveis.
Det gjelder langt utenfor programmering. Mange former for kunnskapsarbeid som ofte omtales som særegent menneskelige, er i praksis langt mer metodiske enn utøverne gjerne vil innrømme.
Dette har ubehagelige implikasjoner. Når arbeid består i å hente inn informasjon, anvende en innlært metode, produsere en vurdering og revidere den mot en form for tilbakemelding, vil agenter trolig forbedre seg raskt.
I den forstand er agentisk KI ikke bare en utfordring for rutinearbeid. Det er også en utfordring for profesjoner der autoriteten hviler på metodisk ekspertise.
Ansvarlig bruk krever mer enn entusiasme
Det betyr ikke at svaret er å «handle raskt og håpe på det beste». Risikoene er reelle. Agenter kan produsere plausible, men feilaktige resultater, feile uten å varsle og oppmuntre til overdelegering dersom de brukes uforsiktig. I vitenskapelige og profesjonelle sammenhenger kan det få alvorlige konsekvenser.
Menneskelig ansvar forsvinner ikke når en agent er involvert.
Hvis et resultat godkjennes, leveres eller brukes i beslutninger, ligger ansvaret fortsatt hos menneskene og organisasjonene som valgte å basere seg på det.
Ansvarlig bruk krever derfor styring fra starten av. Når implementering blir billigere, blir kvaliteten på oppgavebeskrivelsen viktigere. Uklare intensjoner, manglende rammer og underspesifiserte randtilfeller forsvinner ikke når agenter kommer inn i løkken; de får større betydning. Resultater må kunne gjennomgås og etterprøves, tilganger må avgrenses, og team må beholde nok fagkunnskap til å stille kritiske spørsmål ved og verifisere det agenten gjør. Kanskje viktigst av alt må organisasjoner unngå gradvis kompetanseerosjon:
Hvis for mye dømmekraft delegeres for tidlig, kan man miste ekspertisen som trengs for å oppdage når systemet tar feil.
Målet er ikke å unngå agentisk KI, men å bruke den på måter som bevarer tillit, faglig grundighet og ansvarlighet.
For forskere og våre samarbeidspartnere
For forskere, organisasjoner som SINTEF og våre samarbeidspartnere i næringsliv og offentlig sektor kan denne endringen bli dyptgripende. Agentisk KI komprimerer avstanden mellom idé og resultat. Informasjonsinnhenting, utvikling av data- og beregningsmodeller og analyse vil trolig gå raskere. Men det fjerner ikke behovet for ekspertise og kvalitetssikring. Det gjør det enda viktigere å stille riktige spørsmål, definere oppgaven godt og vurdere om resultatene faktisk er korrekte og nyttige. Dermed blir dyp fagkunnskap viktigere, ikke mindre viktig.
Samtidig åpner agentisk KI en ny mulighet: å bygge agentiske grensesnitt rundt avanserte modelleringsverktøy, slik at kapabiliteter utviklet over mange år kan gjøres tilgjengelige ikke bare for flere fageksperter, men også for ikke-eksperter, ved å oversette mellom hverdagsspråk og det formelle språket disse systemene krever.
For samarbeidspartnere i næringsliv og offentlig sektor gir den samme utviklingen både en mulighet og et press. Skreddersydde verktøy, grensesnitt og analyser blir billigere og raskere å bygge, noe som gjør nye typer løsninger mulig. Samtidig risikerer organisasjoner som ikke utvikler egen forståelse av hvor og hvordan agentisk KI kan brukes – altså systemer som kan lære og utføre strukturerte metoder, ikke bare generere tekst eller kode – å bli forbigått av dem som gjør det.
De største gevinstene vil neppe komme fra individuell bruk alene. De vil tilfalle organisasjoner som klarer å identifisere hvilke deler av arbeidet som er strukturerte nok til å akselereres, bygge kompetansen som trengs for å styre, verifisere og kritisk vurdere KI-støttede resultater, og designe nye arbeidsflyter, roller og grensesnitt slik at agentiske systemer blir en del av hvordan organisasjonen faktisk arbeider.
I mellomtiden vil vi i SINTEF AgentLab fortsette å eksperimentere, bygge og dele det vi lærer.
Videre lesning
Punktene nedenfor wr ikke ment som en formell referanseliste, men som et utvalg artikler, blogginnlegg og andre tekster vi har funnet nyttige og tankevekkende i arbeidet med agentisk KI.
- Agoda. From implementers to solution architects: why AI makes your specs the new bottleneck — om hvordan KI-støttet programvareutvikling endrer ekspertens rolle fra manuell implementering til arkitektur, intensjon og verifikasjon.
- Anthropic. Long-running Claude for scientific computing — om hvordan flerdagers agentiske kodearbeidsflyter kan brukes på oppgaver innen vitenskapelige beregninger, og hvorfor fremdriftsfiler, referanseimplementeringer og eksplisitte suksesskriterier er viktige.
- D. E. Knuth. Claude’s Cycles — Donald Knuths egen beretning om å arbeide med Claude på et grafteoretisk problem, og et slående eksempel på hvordan agentisk KI begynner å få betydning selv i avansert matematisk arbeid.
- J. Krys. On theoretical physics, AI and human creativity — en tankevekkende kommentar til nyere KI-fremgang i teoretisk fysikk, og hva den kan innebære for kreativitet, spesialisering og vitenskapelig dømmekraft.
- L. de Moura. Proof Assistants in the Age of AI — om hvorfor formell verifisering, lesbare spesifikasjoner, uttrykksfulle grunnlag og gode verktøy er enda viktigere når KI genererer bevis, og hvorfor verifisering alene ikke fjerner den menneskelige byrden med å formulere riktig teorem.
- S. Sado. Can you relicense open source by rewriting it with AI? The chardet 7.0 dispute — en detaljert juridisk og styringsrettet diskusjon om KI-assistert reimplementasjon, relisensering, og spørsmål om forfatterskap og opphav som oppstår når agenter brukes til å skrive om eksisterende programvare.
- M. Schwarz. Vibe physics: The AI grad student — om å veilede Claude gjennom et reelt teoretisk-fysikk-prosjekt, og om forskjellen mellom imponerende autonom fremgang og vitenskapelig troverdige resultater.
- G. Sivulka. Institutional AI vs individual AI — om hvorfor de største gevinstene fra KI kanskje ikke kommer fra individuell produktivitet alene, men fra redesign av arbeidsflyter, koordinering og formålsbygde verktøy på organisasjonsnivå.
- T. Tao et al. Mathematical exploration and discovery at scale — arXiv-artikkel om AlphaEvolve, testet på 67 matematiske problemer, med forbedringer over gjeldende state-of-the-art i flere tilfeller.
- A. V. Tobias & A. Wahab. Autonomous “self-driving” laboratories: a review of technology and policy implications — en oversiktsartikkel om hvordan KI og laboratorieautomatisering kombineres for å lukke løkken mellom hypotese, eksperiment og analyse innen kjemi, materialvitenskap og biologi.

Matematikk og kybernetikk i SINTEF Digital
Anvendt beregningsvitenskap
Forskningsgruppen utvikler avanserte numeriske metoder og algoritmer for å modellere komplekse fysiske systemer.
Dette gjøres innen geoenergi og elektrokjemi, samt problemstillinger tilknyttet overflatevann og oseanografi.








Kommentarer
Ingen kommentarer enda. Vær den første til å kommentere!