


Mer strukturert informasjon kan gi bedre forebygging og mer rettferdige forsikringsordninger.
Når kraftig regn fører til oversvømmelser, når høststormer river av tak, eller når jordmassene raser ut etter perioder med nedbør og snøsmelting, sitter noen igjen med skadene. I Norge har vi god forsikringsdekning og vi er vant til at forsikringer dekker store deler av de materielle tapene. Men vi har ingen samlet oversikt over hva klimarelaterte natur- og værskader faktisk koster oss. Og enda viktigere, vi har heller ikke klart å bygge et felles system for hvordan vi registrerer, forstår og deler denne typen data.
Denne mangelen på oversikt er et økende problem når klimaendringene gjør at ekstremværet både blir hyppigere og mer alvorlig. I 2024 var de globale tapene som følge av natur- og værskader på rundt 320 milliarder dollar, ifølge Munich Re. I Norge registreres titusenvis av skader årlig. Likevel mister vi verdifull innsikt fordi dataene er spredt hos forsikringsselskaper, i kommunale arkiver, hos statlige aktører og forskningsmiljøer som opererer med ulike modeller, systemer og begreper.
Etter flere års arbeid kom det i 2018 i stand en avtale mellom Finans Norge og DSB (Direktoratet for samfunnssikkerhet og beredskap) om deling av forsikringsdata og samarbeid om risiko- og skadeinformasjon. Denne avtalen ble videreført gjennom samarbeid og datautveksling for å gjøre skadedata tilgjengelig i Kunnskapsbanken for forebygging og risikoanalyse. Dessverre har dette viktige arbeidet stoppet opp.
Arbeidet som ligger til grunn for dette innlegget, bygger på forsikringsdata delt med kommunene gjennom Kunnskapsbanken.
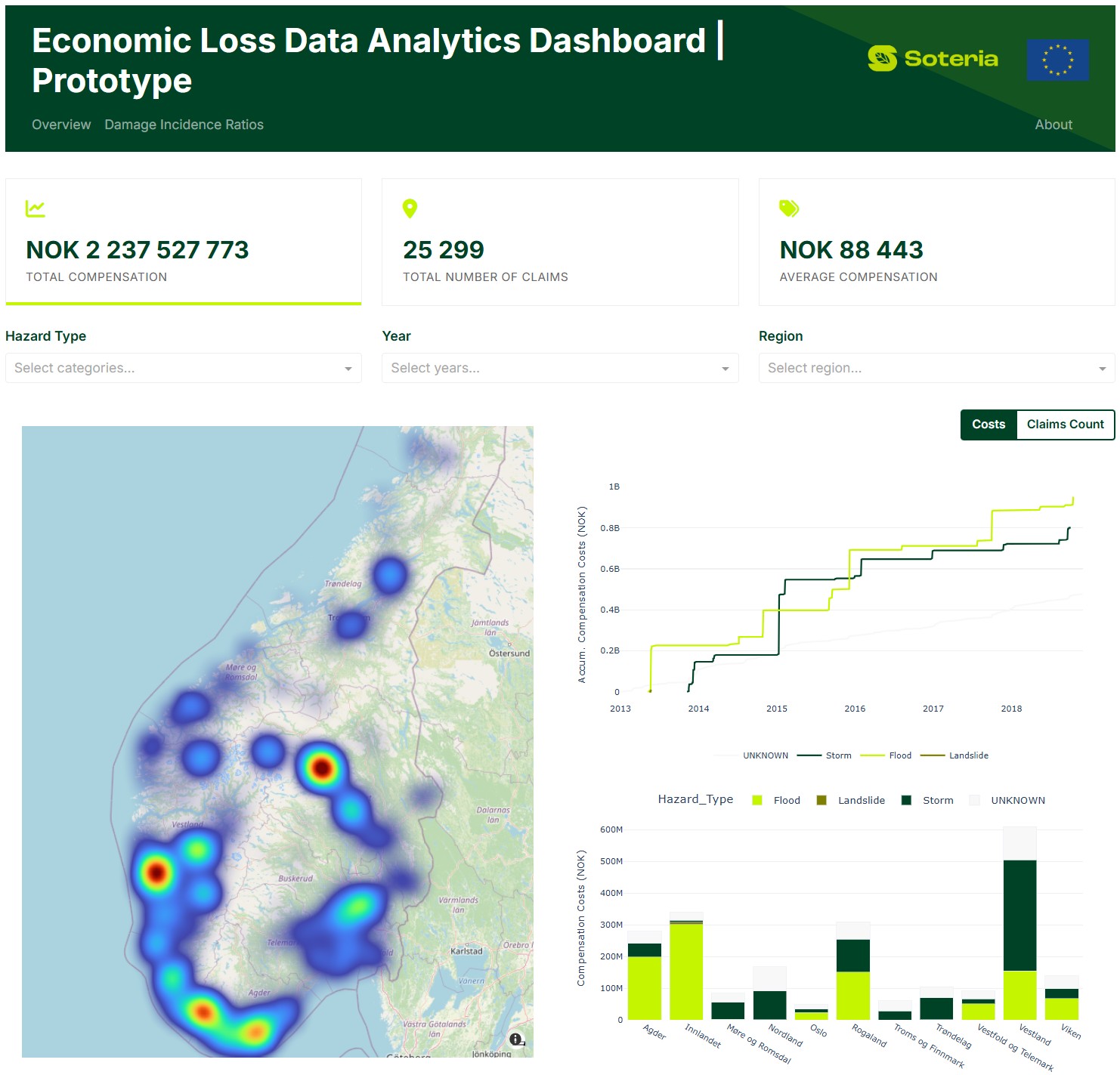
Vi presenterer det vi kaller SOTERIA-ontologien, et nytt rammeverk som gjør det mulig å samle, standardisere og analysere klimarelaterte økonomiske tap på tvers av sektorer, og en prototype webapplikasjon som demonstrerer ontologien i bruk med norske forsikringsdata fra NASK for perioden 2013-2018.
Resultatet er mer enn et teknisk verktøy, det er et felles språk for å forstå klimarisiko. Et skjermbilde av hovedvisningen for webapplikasjonen er presentert over.
Et fragmentert europeisk landskap – og hvorfor det er et problem
De fleste tror kanskje at skadedata er relativt enkelt å samle inn: et bygg blir skadet, noen registrerer det, og tallet havner i et system. Virkeligheten er mye mer komplisert.
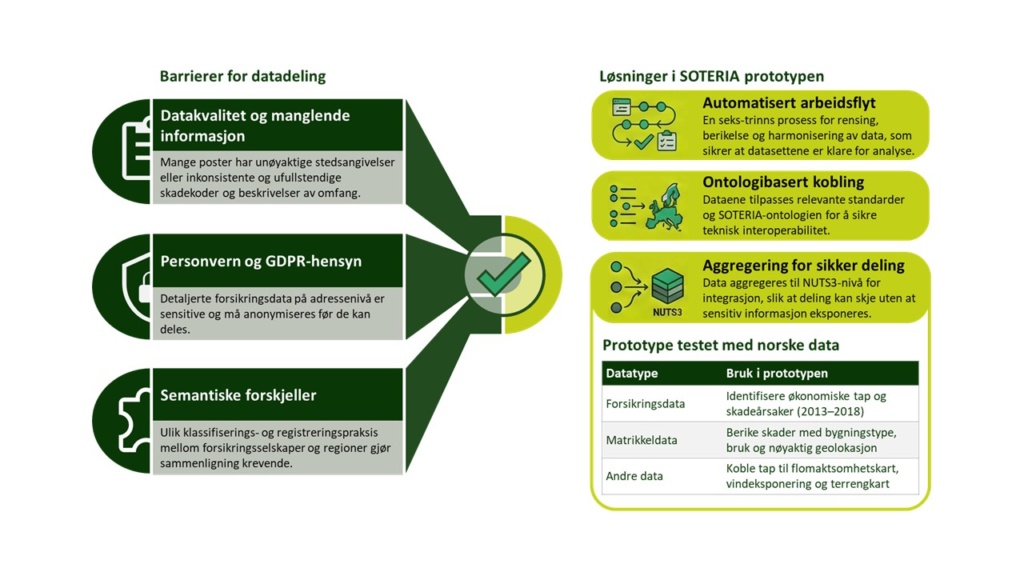
Forsikringsselskaper registrerer detaljerte skader og tap, men i sine egne formater, kategorier og koder. Kommuner har også oversikter, men ikke de samme som forsikringsselskapene, og ofte på et mer aggregert geografisk nivå enn adressenivå. Statlige foretak og forskere lager ulike typer risiko-, og faresonekart som ikke alltid er koblet direkte til historiske skader, men bygger på andre kilder. Og selv innenfor én og samme sektor kan datastrukturen og definisjoner variere i stor grad.
Det fører til tre hovedproblemer:
- Manglende sammenlignbarhet: Definisjoner varierer mellom land og aktører, og data lagres i ulike formater, språk og valutaer.
- Store hull i datagrunnlaget: Selv små variasjoner i adresser eller tidsangivelser kan gjøre det vanskelig å koble skaden til en konkret hendelse eller et konkret bygg.
- Lite effektiv gjenbruk av data: Kommuner, statlige etater og forskningsmiljøer må ofte gjøre samme ryddejobb om igjen, fordi ingen har en felles struktur å lene seg på.
Kort fortalt: Vi har mye data, men vi mangler infrastrukturen som gjør dataene nyttige.
Tenk deg et kart over Norge der alle skader kan kobles til riktig bygg og riktig værhendelse
I prosjektet SOTERIA lagde vi akkurat dette i en pilot basert på norske data. Forsikringsskader på adresse-nivå fra NASK for perioden 2013–2018 ble kombinert med:
- bygningsdata fra matrikkelen
- NVE aktsomhetskart for flom
- vindeksponeringskart (Global Wind Atlas)
- administrative inndelinger (NUTSregioner og postnummer), eiendomsverdier, bygningsfotavtrykk og høydeinformasjon
Når alt dette kobles sammen i en kunnskapsgraf, som tar hensyn til både hva et objekt (f.eks. en bygning) er og hvordan det henger sammen med andre data, får man et helt nytt bilde av klimarisiko.
Og resultatene er talende.
Dette fant vi: Klare mønstre i et tilsynelatende kaos
Flomskader følger elvene, men opptrer også i avstand fra aktsomhetssoner
Når man analyserer skader mot avstand til aktsomhetsoner for flom, synker antall skader allerede etter én kilometer. Dette gir et tydelig, men ikke uventet signal: Avstand til elv betyr noe, og det kan brukes både i arealplanlegging og i forebygging. Men analysene viser også et ikke ubetydelig antall flomskader utenfor aktsomhetsoner for flom.
Flest stormskader på kysten, men ikke nødvendigvis i de mest vindutsatte områdene
Datasettet viser at de største økonomiske tapene ligger i områder med moderat vindeksponering, ikke der vinden er aller sterkest. Antall bygg, standard på bygninger og arealbruk er viktigere faktorer.
Større grunnflate gir høyere flomskadeutbetalinger
Det virker opplagt, men det gir viktig innsikt og verdi i å få dokumentere: Bygninger med stort fotavtrykk medfører større økonomiske tap. Dette er relevant for prising av forsikring, utforming av regelverk og for kommuners og utbyggeres prioriteringer.
Vi mangler fortsatt viktig informasjon
Eksempelvis mangler rundt 38 % av skadene kobling til matrikkeladresse i rådata. Det betyr at mange skader ikke kan knyttes til et konkret bygg uten omfattende manuell innsats. Dette er et av hovedargumentene for standardisering: Bedre data ved kilden gir enorm gevinst nedstrøms.
Hvorfor semantikk (læren om betydning) er nøkkelen – og ikke bare «mer data»
Tradisjonelle databaser jobber med tabeller, rader og kolonner. Men klima- og naturskadedata fungerer ikke slik. De er dynamiske og komplekse: én hendelse kan skade mange bygg, én bygning kan ha mange typer skader, og én skade kan utløse flere forsikringskrav. Å få fram dette i et vanlig databasesystem kan bli tungvint.
En ontologi, et formelt, maskinlesbart begrepsapparat, gjør derimot tre ting:
- Skaper et felles språk på tvers av aktører
- Gjør relasjoner eksplisitte, slik at maskiner kan forstå sammenhenger
- Legger til rette for gjenbruk, deling og avansert analyse
SOTERIA-ontologien er spesielt utviklet for økonomiske tap knyttet til klima, det gjør den unik i europeisk sammenheng.
Hva betyr ontologien og prototype-webapplikasjonen for kommuner, myndigheter og innbyggere
Kommuner får bedre grunnlag for klimatilpasning
Med tilgang til harmoniserte datasett kan kommuner:
- identifisere risikoområder mer presist
- prioritere vedlikehold av kritisk infrastruktur
- planlegge arealbruk basert på dokumentert risiko
- gjennomføre mer målrettede analyser av sårbarhet
Forsikringsbransjen får bedre modeller
Forsikringspremier og vilkår er avhengige av gode risikomodeller. Bedre datakvalitet betyr:
- mer presis prising
- mulighet for nye differensierte produkter
- bedre forståelse av klimarelaterte tapsdrivere
Staten får økt kapasitet til nasjonal styring
En datamodell som SOTERIA-ontologien gjør det enklere å:
- vurdere effekten av klimatilpasningstiltak
- dokumentere økonomiske konsekvenser av ekstremvær nasjonalt
- levere data til EUs Risk Data Hub
Innbyggerne får bedre sikkerhet og mer rettferdige ordninger
Når klimarisikovurderingene blir mer presise, kan tiltakene målrettes der de faktisk virker. Det gir tryggere lokalsamfunn og et mer robust Norge.
Veien videre: en felles europeisk standard?
Arbeidet viser at det ikke bare er Norge som mangler helhetlige datastrukturer. Dette er et europeisk problem. EU har etterlyst bedre rapportering, bedre deling og mer harmonisering – men har foreløpig ikke etablert en fullverdig standard for økonomiske tap. Resultater fra SOTERIA viser at det er mulig.
Hva er behovet nå
- Dagens løsning er tuftet på deling av data på adressenivå. Det er behov for å utforske hva som er tilstrekkelig anonymisering og skalering for å dele data i tråd med GDPR-regelverk og utvikle metodikk for dette.
- Fortsette dialogen med relevante etater som Miljødirektoratet, DSB, NVE og KS (kommuner), Statsforvalteren og forsikringsbransjen om hvordan vi kan utvikle en løsning som gir samfunnsøkonomisk merverdi og nytte i klimatilpasningsarbeidet over tid
- Videreutvikle ontologien. Den nåværende versjonen fokuserer på økonomiske tap fra klimarelaterte naturfarer, men er utformet for fremtidig utvidelse. Dette kan inkludere vannrelaterte skader som ikke klassifiseres som naturfarer (f.eks. nedbør og overvann i urban bebyggelse), ikke-økonomiske tap, samt meteorologiske data for avansert modellering og tidlig varsling.
- Skalere løsningen til andre land, slik at den kan testes og tilpasses ulike nasjonale datasett, standarder og behov.
Men kanskje aller viktigst både for forskningen og samfunnet: Det ligger et stort uutnyttet potensial i å bruke denne typen kunnskapsgrafer sammen med kunstig intelligens. Når store språkmodeller kan spørres direkte mot strukturerte data, åpner det for helt nye arbeidsmetoder i forvaltning, beredskap og planlegging.
Konklusjon
Klimarisikoen øker, og datagrunnlaget vi bruker for å møte den må bli bedre. Vi trenger ikke bare mer informasjon, vi trenger strukturert informasjon som kan deles, forstås og analyseres på tvers av sektorer. SOTERIA-ontologien og den norske pilotstudien viser hvordan dette kan gjøres i praksis.
Hvis vi klarer å etablere et felles språk for klimarelaterte økonomiske tap, står vi langt sterkere i møte med morgendagens ekstremvær.
Les artikkelen: An Ontology-Centered Approach to Climate Loss Data Integration and Analytics – ScienceDirect







Kommentarer
Kjempebra arbeid! Kunnskap vokser når den deles og nå har dere plantet det som nok blir stammen på en mer strukturert, digital og progressiv klimatilpasning. Dette støtter Norsk Wavin!