


For å nå ambisiøse klimamål, trenger vi gode planer. Derfor har EU-landene nylig oppdatert sine nasjonale energi- og klimaplaner (NECP) for perioden 2021-2030. Disse planene skal koordinere innsatsen mot et nullutslippssamfunn, sikre energiforsyninger og legge til rette for bærekraftig økonomisk vekst. Innsikten fra planene kan legge grunnlaget for realistiske modellsimuleringer for utviklingen av det europeiske energisystemet frem mot 2050. Men planene er lange og byråkratiske, og det er derfor tidkrevende (og kjedelig) å manuelt grave frem informasjon.
Gjennom perioden som sommerforsker hos SINTEF Energi har jeg derfor utviklet et KI-drevet program som automatisk kan hente ut informasjon fra NECPer som er relevant for energisystemmodellen GENeSYS-MOD. Systemet er lagd for å gjenkjenne hvilke deler av teksten som inneholder relevante parametere, for eksempel planlagte utslippskutt eller investeringer i fornybar energi, og hente dette ut på en oversiktlig måte. Grunnlaget for applikasjonen er Python-biblioteket Haystack, hvor man har tilgang til det nyeste innen språkbehandlingsteknologier i et lett og intuitivt rammeverk.
Forfatter Simon Wego er sommerforsker hos SINTEF Energi, sommeren 2025. Vil du også bli sommerforsker? Følg med på Energisommerjobb 2026. Stillingene lyses ut i oktober.
Teknologien som blir brukt heter “Retrieval-Augmented Generation” (RAG) og går ut på at man deler opp dokumentet i håndterbare avsnitt og henter avsnitt som er relevante for en gitt forespørsel (retrieval) før man lar en stor språkmodell oppsummere innholdet fra de relevante avsnittene (generation).
Fordelen med å bruke en slik prosesskjede (pipeline) fremfor kun å bruke en stor språkmodell (som 4o-modellen fra OpenAI) er bl.a. at man i større grad kan kontrollere hvor i teksten informasjonen kommer fra, i tillegg til at det er lettere å tilfredsstille krav til skalerbarhet, reproduserbarhet og forutsigbarhet.
Men hvordan kan dette systemet “forstå” hvilke deler av dokumentet som er relevante for forespørselen?
Her kommer en viktig del av moderne språkbehandling inn i bilde – nemlig embeddinger. En tekst-embedding er en oversettelse av naturlig språk til en numerisk vektorrepresentasjon som det er lettere for språkmodeller å jobbe med.
I motsetning til klassiske oversettelser av språk til tallrepresentasjoner, som ofte bare er én-til-én oversettelser mellom ord og tall, har embeddinger den fordelen at de koder semantikk inn i de numeriske vektorene. Det vil si at disse vektorene inneholder informasjon om hva ordene de representerer betyr gjennom forholdet til andre vektorer.
La oss se på et eksempel for å klargjøre dette. Vi tar utgangspunkt i ordene Tyskland og Berlin og oversetter disse til hver sin vektorrepresentasjon ved hjelp av en embedding-modell. Hvis vi da ser på vektorrepresentasjonene til Tyskland og Berlin vil vi oppdage at de peker i omtrent samme retning i vektorrommet fordi de begge er relatert til noe tysk. I tillegg, hvis vi tar Berlin-vektoren og trekker fra Tyskland-vektoren, så kommer den resulterende totalvektoren mest sannsynlig til å være veldig nærme vektorrepresentasjonen til ordet “Hovedstad”.
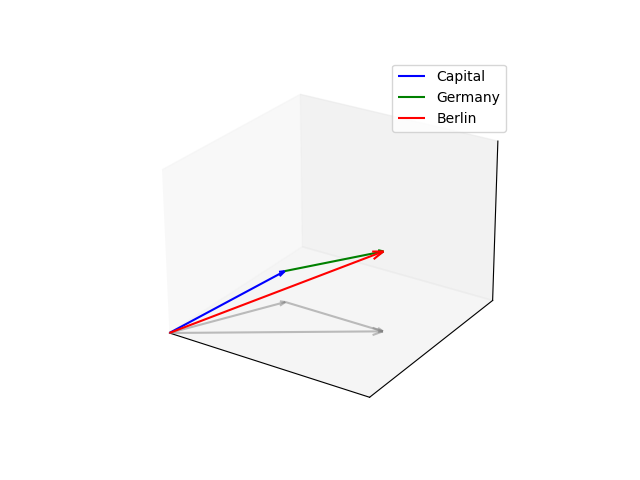
Semantiske søk i RAG
Nå kan vi begynne å se på det fullstendige handlingsløpet i RAG-prosesskjeden. Det hele starter med at en NECP-PDF blir preprosessert. Dette innebærer at den originale PDF-filen blir konvertert til Haystack sitt innebygde dokument-format og renset for unødvendige tegn. Deretter splittes dokumentet i avsnitt på ønsket lengde.
Etter denne preprosesseringen blir innholdet i avsnittene oversatt til en samling embeddinger ved hjelp av en embedding-modell. For å fange essensen til avsnittene blir alle embeddingene i et avsnitt aggregert til én embedding-vektor som et slags gjennomsnitt av hele avsnittet.
For å søke etter informasjon i teksten kan man videre formulere et spørsmål som peker på informasjon man ønsker å finne, også oversetter man dette spørsmålet med den samme embedding-modellen man brukte på teksten. Et semantisk informasjonssøk fungerer da ved å finne de avsnittene som har tekst-embeddinger som er nærmest embeddingen til spørsmålet. Fordi vi her jobber i vektorrom, kan vi enkelt regne ut “avstanden” mellom vektorene.
En avstandsscore nær 1 vil bety at vektorene peker i samme retning og indikerer at spørsmål og avsnitt er semantisk like, noe som vil si at det er gode sjanser for at avsnittet da inneholder informasjon som er relevant til spørsmålet.
Styrken til semantiske informasjonssøk ligger i at det er essensen i teksten som avgjør om man får treff med søket. Denne søkemetoden vil fange opp betydningen av avsnitt på tvers av ulike formuleringer i dokumentet og man er dermed ikke avhengig av å finne de riktige nøkkelordene for å oppnå ønsket søketreff.
I tillegg er semantiske søk å foretrekke hvis man ute etter informasjon som blir formidlet på en indirekte måte i teksten. Men, hvis man vet hvordan informasjonen man er ute etter blir formulert i dokumentet, kan det være vel så nyttig å benytte seg av nøkkelordsøk. En annen fordel med sistnevnte søkemetode er at den ikke er like følsom for hvordan man formulerer søkespørsmål som ved semantiske søk.
Sagt på en annen måte: ved nøkkelordsøk vil avsnittene som ordrett inneholder de viktigste nøkkelordene i søkespørsmålet bli hentet, mens ved semantiske søk hentes de avsnittene som i størst grad betyr det samme som søkespørsmålet, ifølge embedding-modellen.
Så, hvordan utnytter vi fordelene ved begge metoder?
Hybridløsning for informasjonssøk
Det fine med RAG-prosesskjeder fra Haystack er at man enkelt kan implementere hybridsøk der man får det beste fra begge verdener.
I hybridsøk blir tekstavsnitt bedømt for sin relevans til søkespørsmål både ved hjelp av semantiske søk og med nøkkelordsøk. For nøkkelordsøk brukes ofte en anerkjent algoritme ved navn BM25 som gir høyere relevansscorer til avsnitt som inneholder de samme nøkkelordene som spørsmålet.
I RAG-prosesskjeden hentes da relevante avsnitt fra teksten både med BM25-algoritmen og med semantisk søk, og etter at disse uavhengige prosessene har funnet avsnittene de mener er mest relevante for spørsmålet, blir de samme avsnittene matet inn i en ny komponent som kalles reranker (også kjent som ranker).
Både semantisk søk gjennom embeddinger og BM25-algoritmen er designet for å være effektive og kunne hente relevant informasjon raskt. Ulempen kan være redusert nøyaktighet. Derfor har vi rerankeren som fungerer som et slags filter og revurderer relevansen til de hentede avsnittene.
Rerankeren er en egen språkmodell som kalles en “cross encoder” og den er trent på å prosessere avsnitt og spørsmål sammen i én input for å vurdere relevans. Dette er forskjellig fra embedding-modellen, som kan kalles en “bi-encoder” fordi den prosesserer avsnitt og spørsmål hver for seg. Rerankeren returnerer det den vurderer som de mest relevante avsnittene med tilhørende relevansscorer (mellom 0 og 1).
Når man har fått et resultat fra rerankeren, er man ferdig med retriever-delen av RAG-prosesskjeden. I applikasjonen jeg har jobbet med, lagres disse resultatene som retriever-logger som bl.a. inneholder søkespørsmål, hentede avsnitt og metadata som sidetallet avsnittet er hentet fra og relevansscore.
Retriever-delen av systemet fungerer som sagt relativt raskt, og da er det en smal sak å få en oversikt over hvilke land sine NECPer som inneholder avsnitt som er relevante for ulike GENeSYS-MOD-parametere. Figuren under viser en relevansscorematrise der grønne ruter viser funn med en relevansscore over 0,8 for ønsket parameter i landets NECP. Tilsvarende er det gule ruter hvis relevansscoren er mellom 0,5 og 0,8, også har vi hvite ruter hvis relevansscoren er lavere enn 0,5.
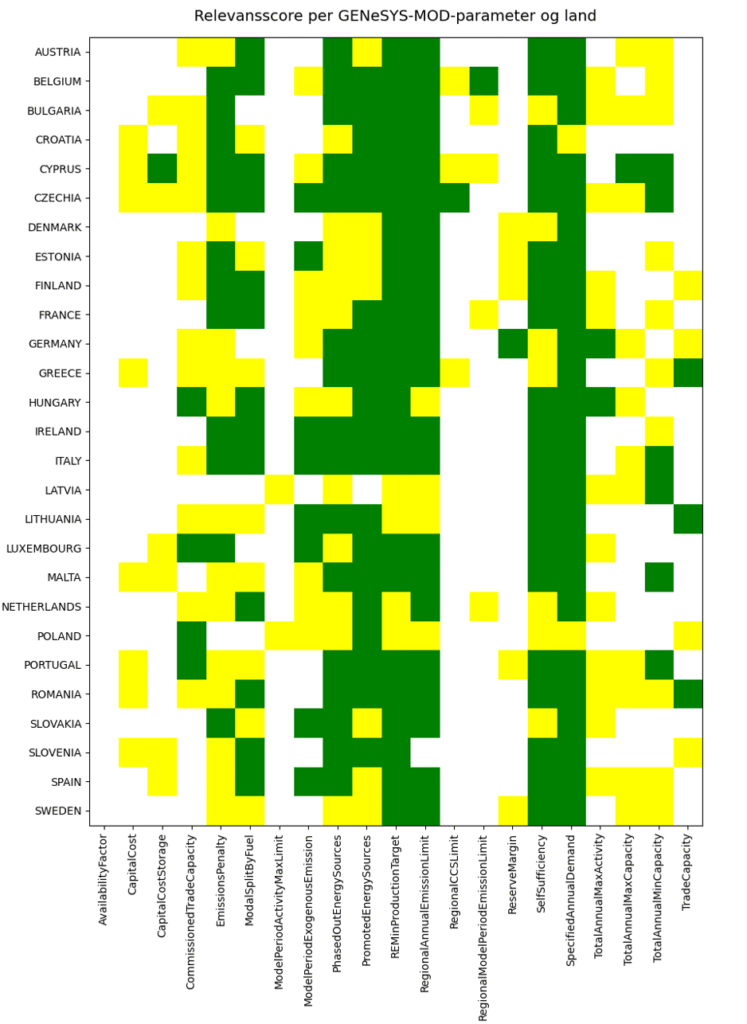
Som vi ser fra figuren virker det som de fleste EU-land nevner i NECPene sine noe relevant knyttet til SpecifiedAnnualDemand- og SelfSufficiency-parameterne, som hhv. handler om prognosert energibehov og selvforsyningsevne, men særdeles få NECPer nevner noe relevant knyttet til parameteren RegionalCCSLimit, som har med lagringskapasitet for klimagasser å gjøre.
“Utfordringer knyttet til presisjon og nøyaktighet vil alltid forekomme når man jobber med KI.”
Med en slik oversikt kan man gå inn i retriever-loggen og lese de hentede avsnittene som har fått høyest relevansscorer for å se om det finnes noen tall eller andre innsikter man kan bruke i energisystemmodellen.
Det må nevnes at selv om et avsnitt får en høy relevansscore fra rerankeren, så betyr ikke det nødvendigvis at det som står i det aktuelle avsnittet svarer på søkespørsmålet på en tilfredsstillende måte. Det kan f.eks. være tilfellet at språket i avsnittet er veldig likt språket i søkespørsmålet uten at det blir nevnt noen spesifikke tall.
På den andre siden er man heller ikke helgardert mot at noen avsnitt som ikke blir oppfattet som relevante faktisk inneholder relevant informasjon. Slike utfordringer knyttet til presisjon og nøyaktighet vil alltid forekomme i mer eller mindre grad når man jobber med KI. Men man kan øke prestasjonen til slike RAG-applikasjoner ved å finjustere språkmodellene med datasett som gir flere domenespesifikke eksempler på hva som regnes som relevante og ikke-relevante avsnitt til et gitt søkespørsmål.
Det som har vært fint med Haystack i denne sammenhengen er at RAG-prosesskjeden har produsert tilfredsstillende resultater uten at noen av de tilgjengelige modellene har trengt å bli finjustert for prosjektet.
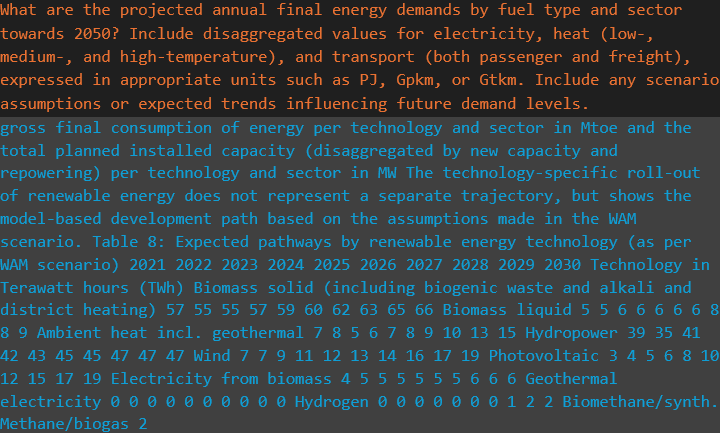
Generativ oppsummering av relevante avsnitt
Videre kan vi redusere mengden tekst vi trenger å lese for å tilegne oss informasjon ved å bruke en språkmodell til å oppsummere de relevante avsnittene for oss. Dette siste steget er generator-delen av RAG-prosesskjeden og her kan man bruke GPTer (Generative Pretrained Transformers) fra f.eks. OpenAI rett inn i Haystack-rammeverket.
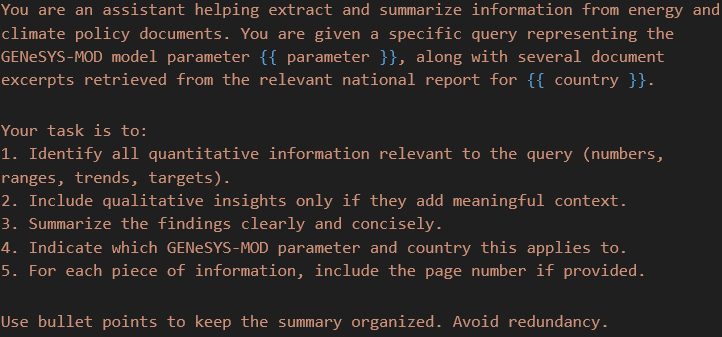
I applikasjonen jeg har jobbet med i sommer brukte jeg en SINTEF-eid Azure-ressurs for å få tilgang til en API-nøkkel som gjorde at jeg kunne benytte meg av OpenAI sin o4-mini-modell som generator. Denne generatoren fungerer akkurat som en chat-modell man møter hos OpenAI. Man gir den et detaljert prompt som beskriver hva den skal gjøre og hvordan den skal bruke de relevante avsnittene den får fra retriever-loggen. Figur 4 viser et eksempel på et slikt prompt.
For hver GENeSYS-MOD-parameter og for hvert land blir svaret fra generatoren lagret i en txt-fil. Figur 5 viser generatoroppsummeringen for SpecifiedAnnualDemand og Østerrike. Slik blir altså relevant informasjon i NECPer samlet og oppsummert av RAG-prosesskjeden, og forhåpentligvis vil resultatene fra dette prosjektet føre til tidsbesparelser i søken etter relevant energi- og klima-data og bidra til mer virkelighetsnære simuleringer av det europeiske energisystemet.
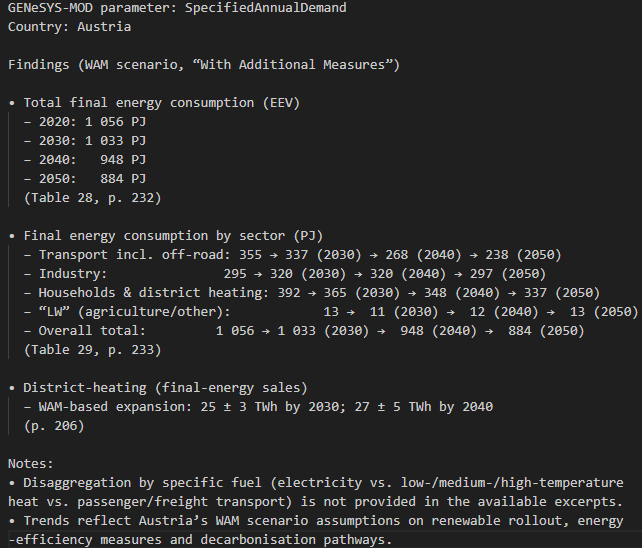
Ved å jobbe på dette prosjektet har jeg fått ta et lite dypdykk i KI-drevne metoder for informasjons-søk og -uthenting. Jeg har lært mye og blitt spesielt fascinert over nytten og elegansen til tekst-embeddinger. Videre har jeg innsett at slike RAG-prosesskjeder er anvendbare i mange andre sammenhenger der det er behov for raske informasjonssøk i ustrukturerte (ikke-tabulerte) tekstdokumenter.
For min egen del er det ikke usannsynlig at jeg kommer til å ta i bruk et tilsvarende system som et hjelpemiddel til litteraturstudie for masteroppgaven til våren. Hvis det virker interessant å utforske tilsvarende informasjonsuthentingssystemer kan jeg anbefale å sjekke ut Haystack.








Kommentarer
Ingen kommentarer enda. Vær den første til å kommentere!